「PDFは見るだけにして欲しい」ができるか?
Excel2007から専用ソフト不要でPDFファイルを作れるようになりました。この結果、メールの添付ファイルやインターネット上でPDFで配布する手段が容易になりましたが、これらのPDFファイルを閲覧専用にしたい場合という状況があります。
ExcelからPDFの出力は、権限の設定ができません。「PDFのデータをExcelで再度使われたくない」ということを想定して、今回は2つのOCRソフトを使ってPDFを「閲覧専用」として作れるか実験テストしてみました。
テスト概要
使用する2つのOCRソフトは共に有償(8000円~10000円前後)のもので、1つは海外製品です。これらのソフトを使ってExcelで作成したPDFファイルを解析させます。
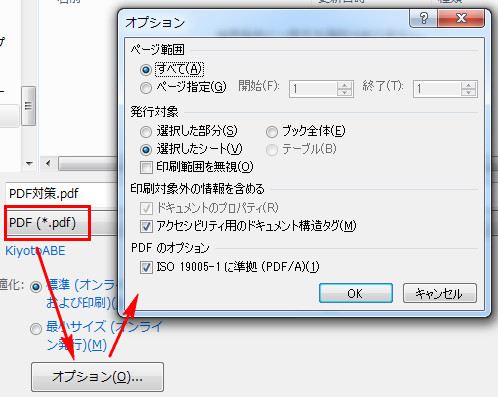
PDFファイルは、Excel2010を使って以下の設定で出力しています。
今回のテストはExcelから直接作ったPDFファイルであり、紙→スキャン→PDFではありません。
読み取らせるPDFのデータは3種類の表で全て同じ内容です(表1と表2は、色を変えただけのものです)。
詳細は下記で実際のExcelデータを見て頂きたいのですが、すべての表でOCRの精度を下げさせること=加工を諦めてもらう、を目的に「細工」をしています。
OCRで読み取れたとしてもExcelの作業が非常に面倒になるようにすることです。
ただし、注意点として、テスト自体がとても緩いです。また本ページの掲載スペース上、デフォルトの結果から更に行列などを一部削除している部分もあります。Excel、OCRソフトともに特に細かい設定までをいじっているわけでもなくざっくり行ったものですので、あくまで参考として見てもらえれば思います。
テスト結果
3種類の表とそれをOCRで読み取らせた結果です(表1と表2は1つのPDFにまとめて作成し、OCRで読み取らせました)。
■表1と表2のPDFファイル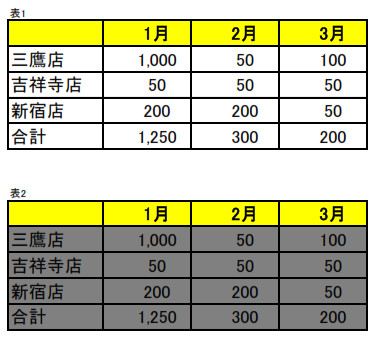
■OCR1(日本製)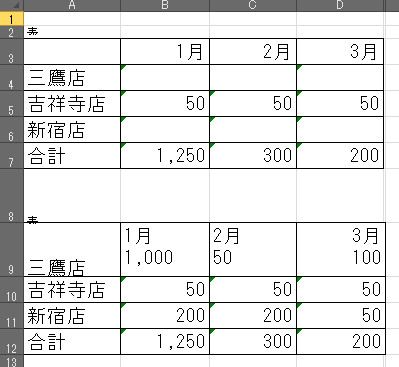
■OCR2(海外製)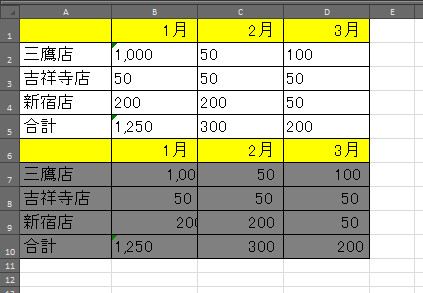
OCR1の表1の結果では、セルが空白のように見える部分がありますが、実際に表全体を選択すると、文字色が白として認識されました。更にその値もPDFと異なっています。
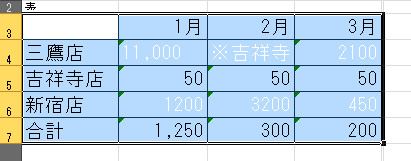
また表2では1行目と2行目が結合されました。
一方OCR2では、なぜか表1と表2がくっついていました。表1が「見た目上」、最もまともですが、1行目の「月」が入力されている行のセルをよく見るとおかしいことが分かります。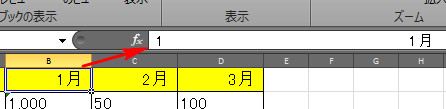
また表2の方では、文字が欠けているセルもありますが、これも中身を見ると下記のようになっていました。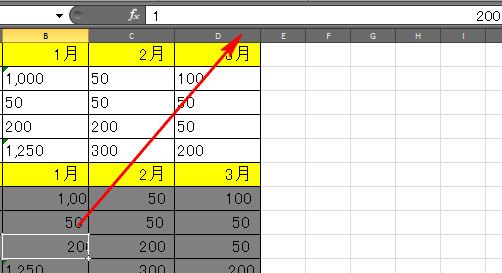
■表3のPDFファイル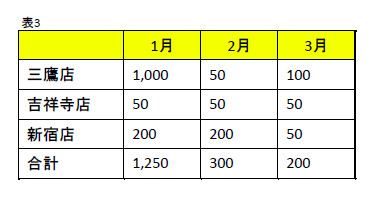
■OCR1(日本製)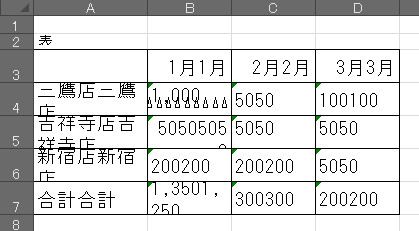
■OCR2(海外製)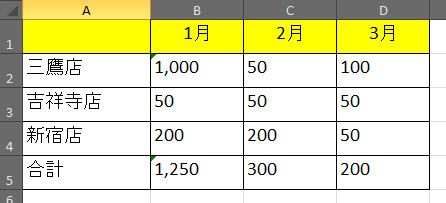
表3では、OCRのソフトで大きな違いがでました。OCR1レベルでは実質Excelに変換できないと言えそうですが、OCR2では、データは完全に同じでExcelに変換すれば再加工可能です。
細工したExcelのデータ
上記の結果を見て、Excel側のシートでどのような細工をしたかお分かりになる方はいらっしゃいますか?
実は表1と表2は案外簡単な細工です。
■表1と表2のExcelデータ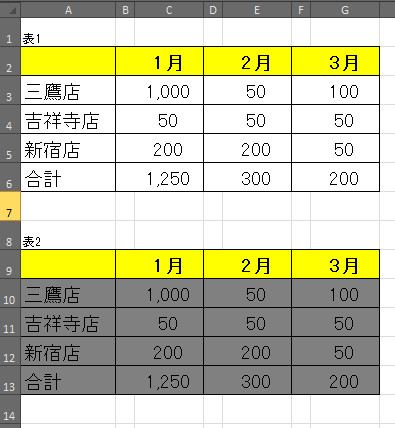
上記の表から、「罫線」、「フォント色」、「フォントサイズ」を変えるとこんな感じです。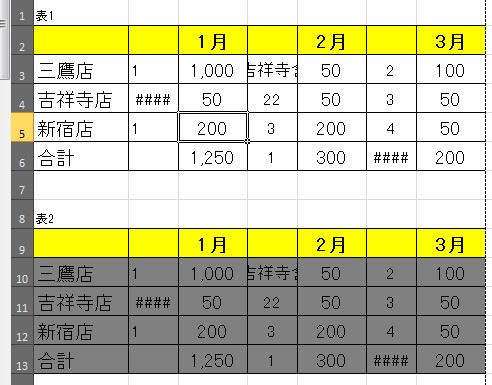
このように「目で見えない部分」を作って、そこにダミーの文字を入れました。OCRでは、この部分をどのように解釈するのかで結果が変わりました。
また、検証結果として、「セルと文字(フォント)の色を変える」とそれなりの効果があるようです。
■表3のExcelデータ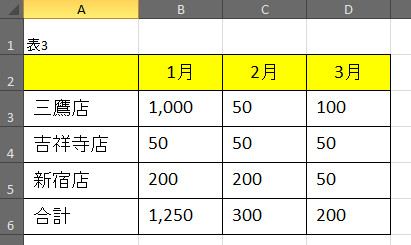
これもExcel上でも見た目は同じですが、次のようにすると何をしているのかわかると思います。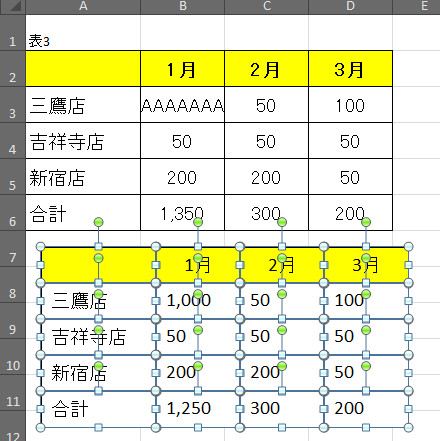
元の表の上に、全く同じサイズの図形を置き、その図形に値を入力しています。そして図形で見えなくなっているセルの値を一部変えていました。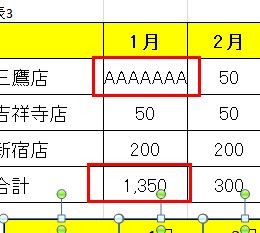
※ちなみに表3だけは、図形のサイズと位置を完全に一致させるためにマクロ(VBA)を使いました
テスト結果で分かったこととは
今回のテストでは、Excelデータにいくつかの細工をして試してみた結果です。想定した以上にOCRソフト結果の開きがあり、最適解を見つけるのがむしろ遠のいた印象です。
またExcel→PDFの流れだけのテストのため紙ベースからのPDFや、OCR側の読み取りに関する細かい設定なども行っていません。
そのため残念ながら、このような状況から言えることはあまりありませんが、ある程度の効果はあるかもしれませんし、細工したデータとOCRソフトとの相性次第では、期待する形にできるかもしれません。
ただ、テストしてて案外面白かったのでこの件についてはまた色々と試してみたいと思います(笑)。